- Published on
Azərbaycan dili üçün fine-tune edilmiş GPT-2 modeli
6 min read
- Authors
- Name
- Nijat Zeynalov
- https://twitter.com



Table of Contents
Azərbaycan dili üçün fine-tune edilmiş GPT-2 modeli
Bu məqalədə OpenAI şirkəti tərəfindən yaradılmış və NLP cəmiyyəti tərəfindən kifayət qədər marağa səbəb olmuş GPT ailəsinin ən çox danışılan üzvündən - GPT-2 modelindən və Azərbaycan dili üçün fine-tune etdiyim gpt2-azerbaijani-small modelindən bəhs edəcəm.
Məqalə aşağıdakı hissələrdən ibarətdir:
- Dil modeli dedikdə nə başa düşək?
- Dil modeli üçün transformerlər
- GPT-2 necə işləyir?
- "gpt2-azerbaijani-smallv0 modeli"-nin train olunması və performansı
Dil modeli dedikdə nə başa düşək?
Dil modelinə belə bir tərif versək, cümlənin əvvəlini nəzərə alıb növbəti sözü proqnozlaşdıra bilən maşın öyrənmə modeli deyə bilərik. Nümunə olaraq, mobil telefonlarımızda olan avtomatik yazma xidmətini göstərə bilərik.
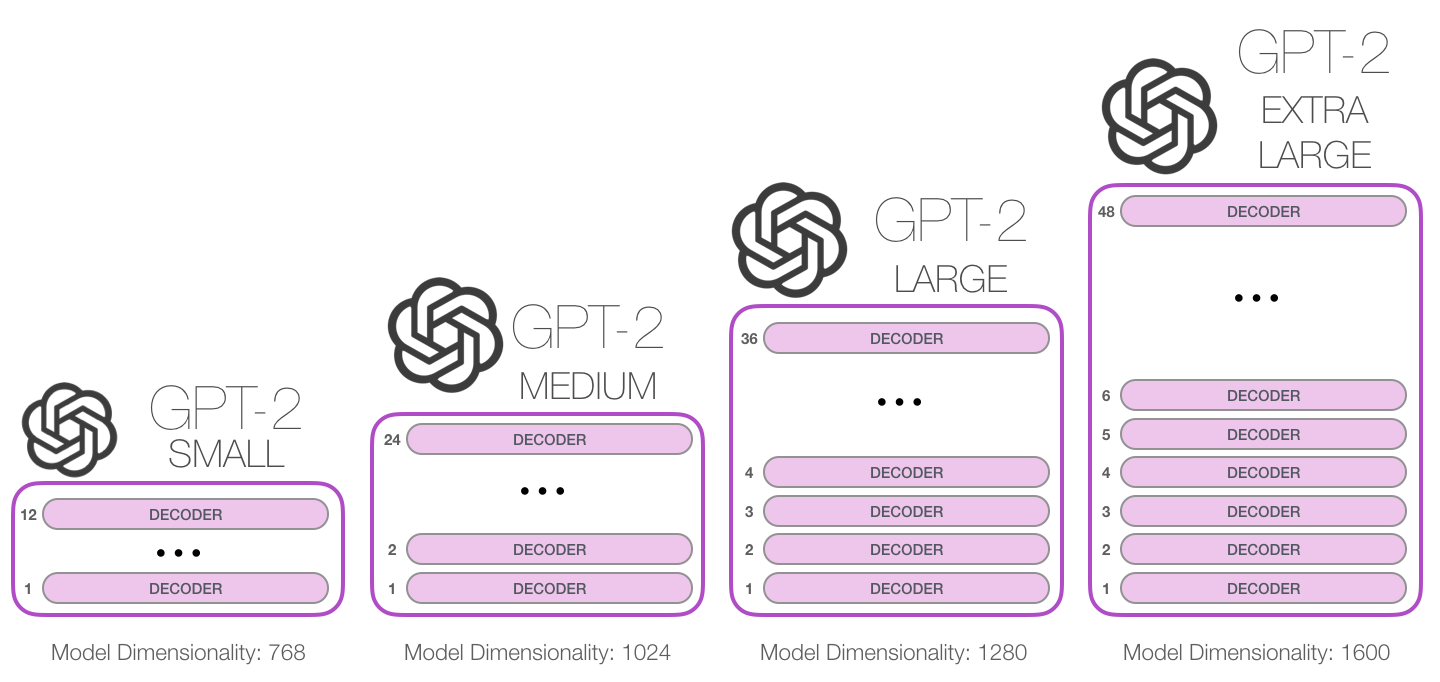
Bu mənada deyə bilərik ki, GPT-2 əsasən klaviatura tətbiqinin növbəti söz proqnozlaşdırma xüsusiyyətidir, lakin telefonunuzda olduğundan daha böyük və daha mürəkkəbdir. GPT-2, OpenAI tədqiqatçıları tərəfindən WebText adlı nəhəng 40GB verilənlər bazası üzərində train edilmişdir. Train edilmiş GPT-2-nin ən kiçik variantı bütün parametrlərini saxlamaq üçün 500MB yaddaş tutur. Ən böyük GPT-2 variantı isə bundan 13 dəfə böyükdür. GPT-2 1,5 milyard parametrə malikdir. Müqayisə üçün deyim ki, bu GPT-1-dən 10 dəfə çoxdur. (117M parametr)
 Original transformer modeli encoder və dekoder adlanan bloklardan ibarətdir. Bu arxitektura uzun müddət uğurlu hesab edilirdi, əsasən də tərcümə üçün istifadə olunan modellərdə çox uyğun idi. Lakin GPT ailəsindən olan modellər, original transformer arxitekturasının encoder hissəsini tələb etmir, enkoder blokları mövcud deyil, başqa şəkildə desək, dekoder enkoderə ekvivalentdir. Enkoder-dekoder arxitekturasından istifadə etdiyimiz hallar, adətən, bir mətnin digər mətnə çevrilməsi zamanı olur.(məsələn: azərbaycan dilindən ingilis dilinə tərcümə modeli)
Original transformer modeli encoder və dekoder adlanan bloklardan ibarətdir. Bu arxitektura uzun müddət uğurlu hesab edilirdi, əsasən də tərcümə üçün istifadə olunan modellərdə çox uyğun idi. Lakin GPT ailəsindən olan modellər, original transformer arxitekturasının encoder hissəsini tələb etmir, enkoder blokları mövcud deyil, başqa şəkildə desək, dekoder enkoderə ekvivalentdir. Enkoder-dekoder arxitekturasından istifadə etdiyimiz hallar, adətən, bir mətnin digər mətnə çevrilməsi zamanı olur.(məsələn: azərbaycan dilindən ingilis dilinə tərcümə modeli)
GPT-2 modeli isə Vikipediya məqalələri kimi mətnlər üzərində öyrədilib. Buna görə də, bu hallarda, yalnız dekoderdən istifadə etməyə daha çox üstünlük verilir.
"gpt2-azerbaijani-smallv0 modeli"-nin train olunması və performansı
Azərbaycan dili üçün GPT modelinin fine tune edilməsi ümumi olaraq aşağıdakı şəkildə göstərilmişdir.

Azərbaycan dilində məqalələrinin və GPT-2 model, tokenizerlərini yükləyirik;
Azərbaycan dili datası ilə GPT-2 tokenizerini train edirik;
Azərbaycan dili datası ilə GPT-2 modelini fine-tune edirik;
İstifadə etdiyimiz wikipedia dataseti Azərbaycan dilində 130k-a yaxın məqalədən və təqribən 14M sözdən ibarətdir. Bu, GPT-2 modelinin üzərində train edildiyi WebText datasetindən 35 dəfəyə yaxın kiçikdir. Rəsmi məqalədə müəlliflər train dataset haqqında bunları qeyd ediblər:
The resulting dataset, WebText, contains the text subset of these 45 million links. To extract the text from HTML responses we use a combination of the Dragnet (Peters &Lecocq, 2013) and Newspaper content extractors. All results presented in this paper use a preliminary version of WebText which does not include links created after Dec 2017 and which after de-duplication and some heuristic based cleaning contains slightly over 8 million documents for a total of 40 GB of text. We removed all Wikipedia documents from WebText since it is a common data source for other datasets and could complicate analysis due to overlapping training data with test evaluation tasks.
Azərbaycan dilində lüğətə malik GPT-2 tokenizer əldə etmək üçün bu addımı həyata keçirməliyik:
Transformers kitabxanasından (Hugging Face) əvvəlcədən hazırlanmış GPT-2 Tokenizer & Modelini (İngilis dili korpusu ilə hazırlanmış) yükləyirik. O, bizə lazım olan tokenizer strukturunu və əvvəlcədən öyrədilmiş model weightlərini verəcək. GPT-2 modelini Azərbaycan train etmək üçün dilində GPT-2 modelimizi təsadüfi weightlərdən başlayaraq öyrətməkdənsə, başqa dildə öyrədilmiş weightlərdən başlayaraq öyrətmək daha məntiqlidir.
Tokenize etmək üçün Byte-level BPE (BBPE) Tokenizer istifadə etmişəm.
Nəticələr
Azərbaycan dili üçün GPT-2 modelinin train olunmasını, Microsoft Azure / GPU - 1 x NVIDIA Tesla K80 üzərində həyata keçirmişəm. Ümumi eksperimentlər 28 saat davam edib, yekun nəticələr: (epoches - 3, loss - 5.17, accuracy - 23.99%, perplexity - 43.88). Aşağıdakı qrafikdə ilk epochdan sonra alınan loss nəticələrini əlavə etmişəm.

İstifadə qaydası
Modeli opensource olaraq huggingface-də paylaşmışam, istifadə qaydası bu şəkildədir.
import torch
from transformers import GPT2LMHeadModel, AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("nijatzeynalov/gpt2-azerbaijani-small")
tokenizer.model_max_length=1024
model_state_dict = torch.load('GPT2_pt_3epoch_lr2e-3.pth', map_location=torch.device('cpu'))
model = GPT2LMHeadModel.from_pretrained('gpt2', state_dict=model_state_dict)
model.eval()
text = "Your prompt here"
inputs = tokenizer(text, return_tensors="pt")
sample_outputs = model.generate(inputs.input_ids,
pad_token_id=50256,
do_sample=True,
max_length=20,
top_k=10,
num_return_sequences=1)
# generated sequence
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
Limitlər
Bu model GPT-2 modelinin Azərbaycan dilinə tətbiqi üçün araşdırma məqsədi ilə hazırlanmışdır və yaratdığı nəticələr resurs limitindən dolayı çox aşağı keyfiyyətlidir, hazirki versiyadan kommersial layihələrdə istifadəsi tövsiyə edilmir.
Mövcud resurslarım əlverişli olmadığı üçün, bu modelə yenidən qayıdacağam, nəticələri yaxşılaşdırmaq üçün planlaşdırıram:
- Azərbaycan dilində daha çox train data əlavə etmək; Təkcə vikipedia üzərindən yox, ümumilikdə müxtəlif resurslardan istifadə edərək, 500k+ məqalə tapıb əlavə etməyi planlaşdırıram.
- Train dataseti daha yaxşı şəkildə təmizləmək; Hazırda resurs azlığından dolayı təmizləmə demək olar ki, edilmir.
- Daha güclü GPU istifadə edərək fərqli eksperimentlər aparmaq. Fine tuning üçün yalnız 1cycle policy Leslie N. Smith et al. in Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. texnikası test edilib.
- Epoch sayını artırmaq; Hazırki GPU (GPU - 1 x NVIDIA Tesla K80) ilə 1 epoch təqribən ~9 saat davam edir ($0.90/hr). Layihənin məqsədini və digər resursları nəzərə alıb, 3 epochda dayandırmağı məqbul görmüşəm.
Digər məsələ isə modelin biased nəticə verə bilməsidir. Buna səbəb, bütün train məlumatların vikipediyadan götürülməsidir və orada süzülməmiş, neytrallığı şübhə doğuran nüanslar ola bilər. OpenAI modelin məqaləsində də qeyd etdiyi kimi:
Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
Bu qədər :) Azərbaycan dilində fine-tuned edilmiş GPT-2 modelinin sıfırıncı versiyasından bu qədər. Qeyd etdiyim kimi, yuxarıda qeyd olunan nüansları nəzərə alıb, bu layihəyə geri dönəcəm. Görüşərik!
Bura qədər gəlmişkən, bir məlumat vermək istəyirəm. Uzun fasilədən sonra, tədrisə yenidən başlayıram. Bu yaxınlarda Python proqramlaşdırma dilinin əsaslarından başlayaraq (yəni, sıfırdan), Machine Learning, SQL, Deep Learning, AWS, TensorFlow kimi önəmli biliklər əldə edə biləcəyiniz unikal sillabusla təlim proqramına başlayacam. Ümumi proqram 8 ay davam edir, ətraflı məlumat üçün buraya klikləyin. Yerlər məhduddur.
Hər birinizə uğurlar arzu edirəm!