- Published on
Datasetin lokaldan S3-ə yüklənməsi, Amazon Athena ilə sorğulanması və formatının dəyişdirilməsi
6 min read
- Authors
- Name
- Nijat Zeynalov
- https://twitter.com



Table of Contents
Amazon S3 ilə bağlı xüsusi məqaləmin olacağını düşünürəm, lakin ümumi olaraq S3 verilənlərin yüksək əlçatanlıq və davamlılıqla saxlanılmasını təklif edir. Biz S3-də olan məlumatları başqa bir yerə köçürmədən Athena interaktiv sorğu xidməti vasitəsi ilə sadə SQL sorğuları icra edəcəyik.
İlk addımda csv fayl formatında olan dataset üzərində sorğular yazacaq, daha sonra isə csv məlumatlarını sorğulamaq üçün optimallaşdırılmış, sütunlu fayl formatı Apache Parket-ə necə asanlıqla çevirəcəyimizi göstərəcəyik.
Bu tutorialda sizə AWS hesabı ehtiyac olacaq və istifadə olunacaq servislər aws free tier-ə daxildir. Ətraflı məlumat və qeydiyyatdan keçmək üçün bu məqaləni oxuya bilərsiniz
Addım 1 — Datasetin kompüterə yüklənməsi
Məqalədə 2019-cu ildə hazırladığım supermarket datasetini istifadə edəcəyik. Datasetdə supermarketin 20 filialında 80 000 müştərinin aldığı 438 826 Azərbaycan məhsulu ilə bağlı məlumatlar toplanıb. (ətraflı məlumat) Dataseti bu linkdən istifadə edərək, kompüterinizə yükləyin.
Datasetin ümumi təsviri bu şəkildədir.

Addım 2 — AWS CLI ilə datasetin S3-ə yüklənməsi
AWS CLI — Command Line Interface (AWS CLI) AWS xidmətlərinizi idarə etmək üçün vahid üsuldur. Komandalar vasitəsi ilə siz bir neçə AWS xidmətlərini konfiqurasiya edə, idarə edə və onları skriptlər vasitəsilə avtomatlaşdıra bilərsiniz.
Ola bilər ki, bizim hazırda istifadə etdiyimiz istifadəçinin S3-ə full icazəsi yoxdur. CLI-dən istifadə edərək AWS-ə daxil olarkən, işləmək niyyətində olduğunuz resurslara kifayət qədər icazəsi olan bir və ya daha çox IAM istifadəçisi yaratmalıyıq. Bu səbəbdən işə yeni IAM istifadəçi yaratmaqla başlayacağıq.
Amazon S3-ə çıxışı olan IAM istifadəçisi yaratmaq üçün əvvəlcə AWS IAM konsolunuza daxil olmalısınız. Access management qrupunun altında Users üzərinə klikləyin. Daha sonra, Add user üzərinə klikləyin.

Ardınca, User name* qutusuna s3Admin kimi yaratdığınız IAM istifadəçisinin adını yazın. Access type* seçimində Programmatic access seçin. Sonra isə Next: Permissions düyməsini klikləyin.

Açılan növbəti səhifədə, Attach existing policies directly üzərinə klikləyin. Sonra, AmazonS3FullAccess siyasət adını axtarın və onu seçin. Bitirdikdən sonra Next: Tags üzərinə klikləyin.

Bundan sonra gələn səhifədə heçnəyi dəyişdirməyərək, nexti seçin və ən sonda create user üzərinə klikləyin.

Nəhayət, istifadəçi yaradıldıqdan sonra siz Giriş açarı ID-sini və Gizli giriş açarı kopyalayıb sonrakı istifadə üçün saxlamalısınız. Biz həmçinin birazdan AWS CLI üçün də bu dəyərləri istifadə edəcəyik.
Nəzərə alın ki, bu dəyərləri yalnız bir dəfə görmə şansınız var.
Kompüterinizdə AWS profilinin qurulması
Amazon S3-ə müvafiq icazəsi olan IAM istifadəçisini yaratdığımız üçün növbəti addım kompüterimizdə AWS CLI profilini qurmaqdır. Bu addım üçün AWS CLI v2 alətini quraşdırmalısınız. Quraşdırmaq üçün linki izləyə bilərsiniz.
Profil yaratmaq üçün sizə aşağıdakı məlumatlar lazımdır:
IAM istifadəçisinin Giriş açarı ID-si. — Access key ID
IAM istifadəçisi ilə əlaqəli gizli giriş açarı. — Secret access key
Defolt bölgə adı — AWS S3 bucketinizin yerləşdiyi regiona uyğundur. Bu məqalədə AWS S3 bucketi US East (N. Virginia)-da yerləşir və endpointimiz us-east-1 dir.
Standart çıxış formatı. Bunun üçün JSON istifadə edin.
Profil yaratmaq üçün cmd və ya terminalı açıb, aşağıdakı komandanı daxil edin. Daha sonra isə yuxarıda qeyd olunduğu ardıcıllıqla məlumatları daxil edin. Access key id və secret access key olaraq bayaq görmüş olduğumuz yeni yaradılmış istifadəçi üçün olan dəyərləri daxil edin.
aws configure

AWS CLI profilini konfiqurasiya etdikdən sonra terminalda aşağıdakı əmri işlətməklə profilin işlədiyini təsdiqləyə bilərsiniz. Bu əmr indiyə qədər yaratmış olduğumuz s3 bucketlərin siyahısını bizə qaytaracaq.
aws s3 ls
Bura qədər problemsiz gəldiksə, əla! 🎉
Növbəti addım isə faylımızı yükləmək üçün yeni bir s3 bucketi yaratmaq olacaq. Bunun üçün elə həmin terminalda aws s3 mb s3://bucketin adı əmrini yazın. Diqqət edin ki, yaratmış olduğunuz bucket adı global olaraq unikaldır, yəni mənim aşağıda yaratmış olduğum adda sizin bucketiniz ola bilməz.

aws s3 ls əmrini təkrarlayaraq bucketin həqiqətən yarandığını görə bilərsiniz.
Bayaq yüklədiyimiz supermarket dataseti hansı qovluqdadır? Bu bizə lazımdır, çünki faylı S3-ə yükləmək üçün aws s3 cp əmrinə iki arqument (mənbə və hədəf) təqdim etməliyik.
Mənbə: faylın bizim komputerimizdəki ünvanı
Hədəf: faylı yükləmək istədiyimiz bucketin ünvanı
Faylın komputerdə yerləşdiyi ünvanı kopyalayın və terminalda aşağıdakı əmri öz vəziyyətiniz üçün dəyişdirərək yazın.
aws s3 cp /Users/nijatzeynalov/Downloads/esas_mehsullar.csv s3://ssupermarket-dataset
ls əmrindən istifadə edərək, faylın həqiqətən bucketimizə yüklənmiş olduğunu təsdiqləyə bilərik.

Addım 3 — Amazon Athena ilə dataset üzərində SQL sorğularının yazılması
Amazon Athena standart SQL istifadə edərək Amazon S3-də olan verilənləri təhlil etməyi asanlaşdıran interaktiv sorğu xidmətidir. Athena ilə biz S3-də olan xam verilənləri, o cümlədən şifrələnmiş verilənləri sorğulaya bilərik.
Athena sorğuların performansını və sürətini daha əlverişli etmək üçün Parquet sütunlu fayl formatını dəstəkləyir. Parquet formatında olan data üzərində sorgular daha sürətli nəticə göstərir.
Athena, böyük verilənlər bazalarında sürətlə işləyən open-source və distributed SQL sorğu mühərriki Presto-ya əsaslanır.
Biz Athena-ya AWS Management Console, API, Open Data‐ base Connectivity (ODBC) və ya Java Database Connectivity (JDBC) driver vasitəsilə daxil ola bilərik. Bu tutorialın əvvəlində yaratdığımız useri istifadə edərək, consoledan daxil olaq.
Səhifədən Explore the query editor üzərinə klikləyin. Yeni açılan səhifədə ilk olaraq sorğu nəticələrimizin hansı s3 bucketə yazılacağını müəyyənləşdirməliyik. Bunun üçün Settings > Manage > Browse S3 seçimini edərək, nəticələri hansı s3 bucketə yazmaq istəyirsinizsə onu qeyd edirsiniz.

Oley! 🎉
İndi sorğularımızı yaza bilərik! İlk olaraq, açılan sql pəncərəsində SQL komandasından istifadə edərək, yeni database yaratmalıyıq. Bunun üçün
CREATE DATABASE mehsullar

İndi isə sıra gəldi, məhsullar üzərində sorğular yaza bilməyimiz üçün table yaratmağa. Bunun üçün yeni sorğu pəncərəsi açıb, aşağıdakı sorğunu daxil edin.
CREATE EXTERNAL TABLE IF NOT EXISTS mehsullar.satis_mehsullar_2019(
id int,
satish_kodu int,mehsul_kodu int,
mehsul_ad string,
mehsul_kateqoriya string,
mehsul_qiymet int,
satish_tarixi string,
endirim_kompaniya string,
bonus_kart string,
magaza_ad string,
magaza_lat float,
magaza_long float
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
LOCATION 's3://ssupermarket-dataset/'
TBLPROPERTIES ('skip.header.line.count'='1')

Əla! cədvəlimiz yarandı! Hər şeyin düzgün işlədiyini yoxlamaq üçün belə bir nümunə sorğu yazaq:
select * from mehsullar.satis_mehsullar_2019 where mehsul_qiymet> 2

Hər şey hazır! 🎊🎉
Əgər diqqət etdinizsə, yuxarıdakı sorğunun nəticəsi 1.869 saniyəyə hazır oldu və ümumilikdə 57.70 mb data skan olundu. Bəs, bunu daha sürətli edə bilərik mi? Yazının əvvəlində də qeyd etdiyimiz kimi, Athena parquet formartında olan data ilə daha sürətli işləyir. Bunun səbəbinə növbəti məqalədə toxunacam, lakin indi table yaradarkən onu necə parquet formatına çevirə bilərik, buna baxaq.
Və ən əsası, görək doğrudan da mı parquet formatında olan data daha sürətli oxunur.
Bunun üçün yenidən Athena servisinin əsas səhifəsinə qayıdırıq. Database olaraq mehsullar seçildiyindən əmin oluruq və Tables and views > Create with SQL > Create table ardıcıllığını həyata keçiririk.
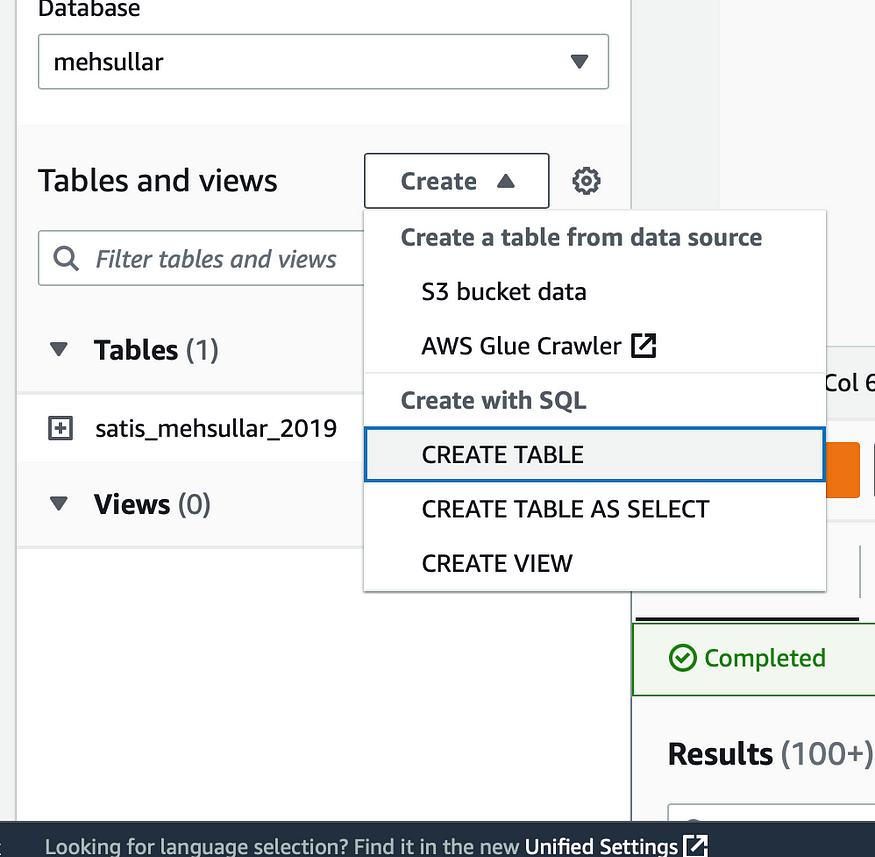
Açılan yeni SQL sorğu pəncərəsinə aşağıdakı sorğunu daxil edin.
CREATE TABLE IF NOT EXISTS mehsullar.satis_mehsullar_2019_parquet
WITH (format = 'PARQUET', external_location = 's3://ssupermarket-dataset/parquet') AS
select
*
FROM mehsullar.satis_mehsullar_2019
Tables bölməsinə baxdıqda yeni yaranmış satis_mehsullar_2019_parquet cədvəlini görə bilərik. İndi isə bayaqki sorğunu yenidən bu cədvəl üzərində yoxlayaq və nəticələri müqayisə edək.
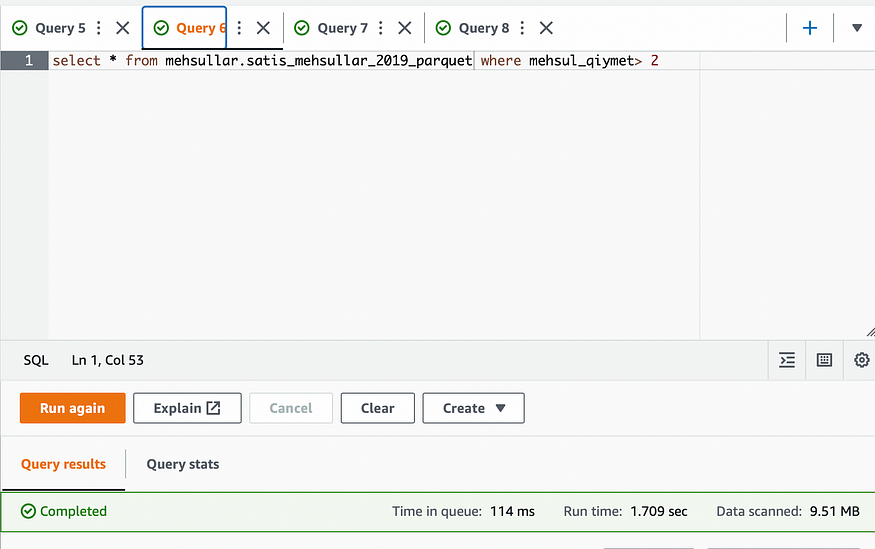
Eyni sorğu, eyni data üzərində :) Runtime 1.869 saniyədən 1.709 saniyəyə, skan olunan data isə 57.70 mbdan 9.51 mbya qədər azaldı. Biz partitionlar verərək, aradakı fərqi daha da artıra bilərik.
Bu məqalədə, aws cli istifadə edərək lokal kompüterimizdə olan datanı s3 bucketinə yükləməyi və athena ilə o data üzərində sorğular yazmağı öyrəndik. Daha sonra isə, dataseti csv\tsv formatı ilə müqayisədə daha sürətli olan parquet formatına çevirərək, nəticələri müqayisə etdik.
Görüşənədək!